A Valuable & Interesting New Product Direction: AI Evaluation Tools (With 5 Case Studies)

As AI products multiply, so does the need for tools that evaluate them objectively.
Below are five real-world cases showing where dedicated AI benchmarking tools are emerging—spanning document parsing, model speed, prompt generation, prompt version management, and even AGI assessment.
Case 1: TextIn – An Evaluation Tool for Document-Parsing AI
The demand for testing document-parsing AI models is rising across varied use cases: annual reports, financial statements, academic papers, policy documents, internal business files, textbooks, exam sheets, formulas, and more.
Currently, evaluating these tools is inefficient—users either run end-to-end tests (which lack granular insight) or manually inspect small samples (which is time-consuming and limited).
Tools like TextIn help users select the best AI for their specific scenario, saving time on testing and comparison.
It evaluates across five dimensions: tables, paragraphs, headings, reading order, and formulas, presenting results in both table and radar chart formats.
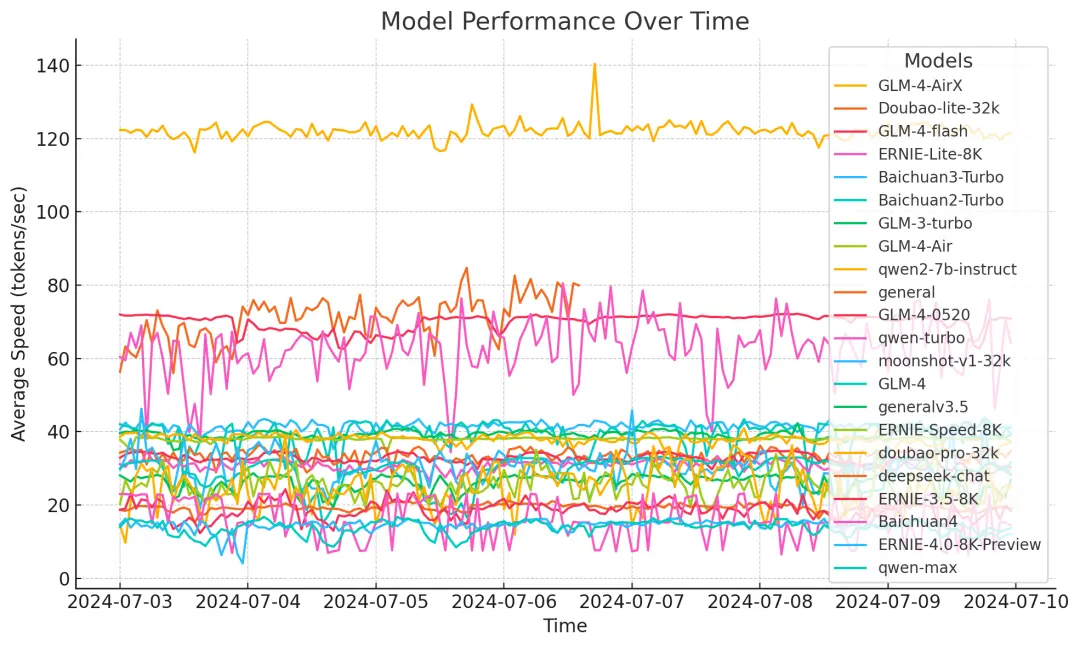
Case 2: LLM Speed Benchmark – “The Real Speed of Large Models”
While AI capabilities often grab headlines, inference speed is critical for real-world deployment.
Several platforms now benchmark and publish comparative speed data for leading LLMs, helping developers choose models that balance performance with latency and cost—a key decision in production environments.
Case 3: Claude’s Prompt Generator – Create, Test & Evaluate Prompts
Powered by Claude 3.5 Sonnet, this feature lets users describe a task and automatically generates high-quality prompts.
You can edit prompts, run them against test cases with one click, and score outputs to track which prompt performs best—turning prompt engineering into a measurable, iterative process.
Case 4: Prompt Version Management & Cross-Model Testing
Similar to code versioning, teams need to track prompt iterations and compare performance across models.
Platforms like Dify allow you to manage prompt histories and test the same prompt across multiple LLMs, making it clear which model works best for a given task.
Case 5: AGI Evaluation – The ARC Prize Initiative
In the article “Zapier’s Founder: Most People Define AGI Wrong!”, the conversation turns to how we measure artificial general intelligence.
The piece mentions the ARC Prizes—a nonprofit public challenge with over $1 million in prizes—designed to advance solutions to the ARC AGI evaluation.
According to the author, the ARC AGI benchmark is one of the few that measures AGI correctly:
- The mainstream definition—AGI as a system that can do most economically valuable work—is misleading and drives overinvestment in scaling language models rather than exploring new ideas.
- A better definition: a system that can efficiently acquire new skills and use them to solve novel, open-ended problems.
- The ARC evaluation focuses on a minimal reproduction of general intelligence, encouraging solutions from outsiders not bound by current LLM paradigms.
Final Thought
Across each case, a pattern emerges: as AI applications grow specialized, so does the need for tailored evaluation tools.
Whether you’re building, buying, or researching AI, consider this:
In your corner of the AI world, is there a gap in how tools are tested, compared, or measured—and could that gap be a product opportunity?
























0 Comment